Architecture¶
hg.mozilla.org is an Internet connected service.
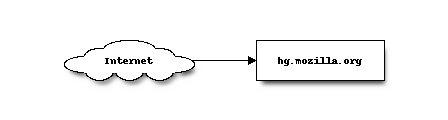
hg.mozilla.org exposes HTTP and SSH service endpoints all running on standard ports. Connections to these services connect to a load balancer.
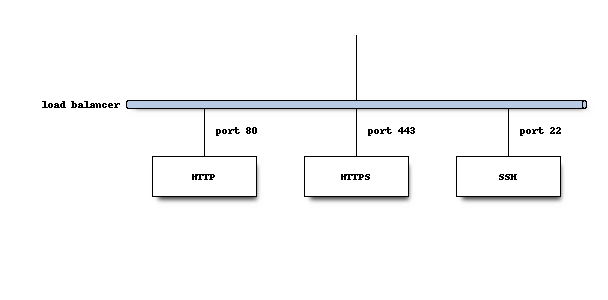
HTTP requests to port 80 are always HTTP 301 redirected to https://hg.mozilla.org/ and come back in via port 443.
HTTPS connections to port 443 are routed to a pool of read-only mirrors. We call these the hgweb servers.
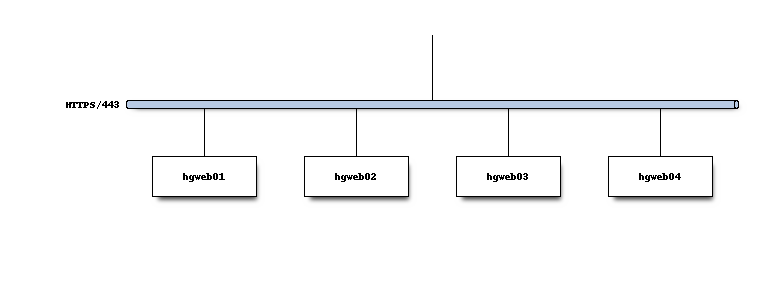
(Server names are representative.)
Each server is identically configured and behaves like the others. HTTP connections/requests are routed to any available hgweb server.
SSH connections to port 22 are routed to a single primary server. There is a warm standby for the primary server that is made active should the primary server fail. We collectively refer to these as the hgssh servers.
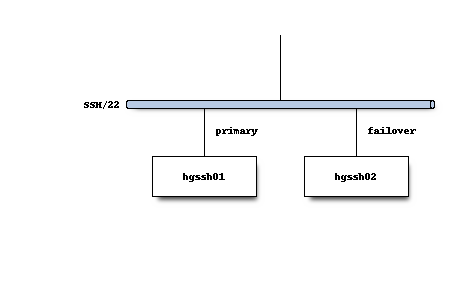
SSH connections use public key authentication. User access control and storage of SSH public keys is stored in an LDAP server.

An authenticated SSH connection spawns the pash.py script from
the version-control-tools repository. This script performs additional
checking of the incoming request before eventually spawning an hg
serve process, which allows the Mercurial client to communicate with
a repository on the server.
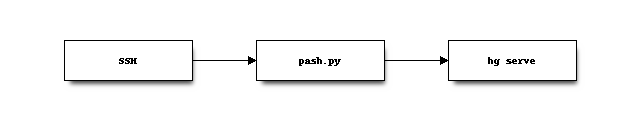
The hgssh servers hold the canonical repository data on a network appliance exporting a mountable read-write filesystem.
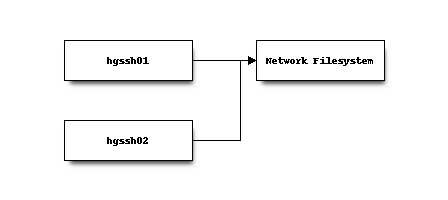
All repository write operations are performed via SSH and are handled by the primary hgssh server.
Various Mercurial hooks and extensions run on the hgssh server when repository events occur. Some of these verify incoming changes are acceptable and reject them if not. Others perform actions in reaction to the incoming change.
In terms of service architecture, the most important action taken in reaction to pushes is writing events into the replication system.
Repository Replication Mechanism¶
See Replication for the architecture of the replication system.
Notifications¶
As described in the replication documentation, there exists a
pushdataaggregator Kafka topic exposing a stream of fully-replicated
repository change messages.
Various services on the active primary hgssh server consume this topic and do things with the messages. One consumer notifies Pulse of repository changes. Another sends messages to AWS SNS.
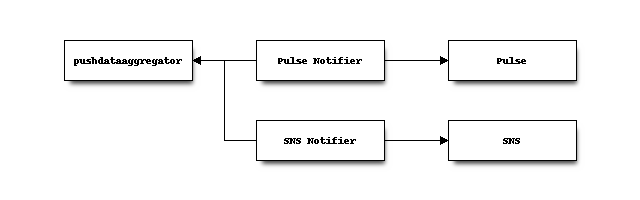
See Change Notifications for more.
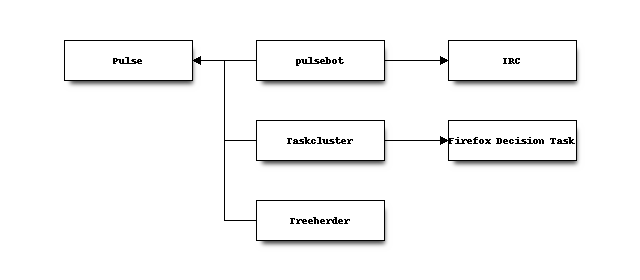
From there, various other services not part of the hg.mozilla.org infrastructure react to events. For example, pulsebot creates IRC notifications, Taskcluster schedules Firefox CI, and Treeherder records the push.
HTTP Repository Serving¶
Nearly every consumer of hg.mozilla.org consumes the service via HTTP: only pushes should be using SSH.
The HTTP service is pretty standard for a Python-based service: there’s an HTTP server running on each hgweb server that converts the requests to WSGI and sends them to a Python process running Mercurial’s built-in hgweb server. hgweb handles processing the request and generating a response.
hgweb serves mixed content types (HTML, JSON, etc) for web browsers and other agents. In addition, hgweb also services Mercurial’s custom wire protocol for communicating with Mercurial clients.
When a client executes an hg command that needs to talk to hg.mozilla.org,
the client process establishes an HTTP connection with hg.mozilla.org and
issues commands to a repository there via HTTP. Run
hg help internals.wireproto for details of how this works.
Clone Offload¶
In order to alleviate server-side CPU and network load, frequently accessed
repositories on hg.mozilla.org use Mercurial’s clone bundles feature so
hg clone operations download most repository data from a pre-generated
static bundle file hosted on a scalable HTTP server.
Most Mercurial clients will fetch a bundle from the CloudFront CDN.
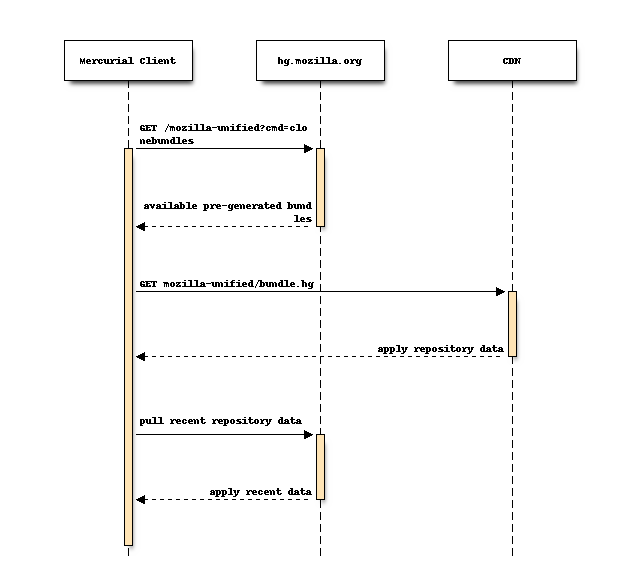
If the client can’t connect to CloudFront (requires SNI) or if the client is connecting from an AWS IP belonging to an AWS region where we have an S3 bucket containing repository data, the client will connect to S3 instead.
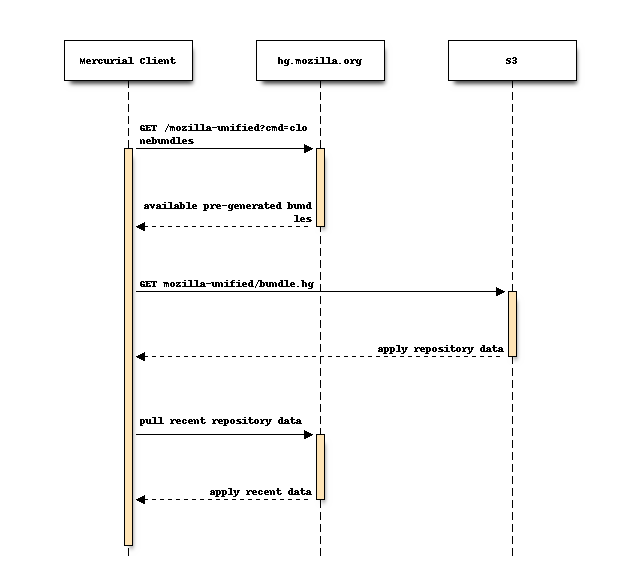
Offloading the bulk of expensive hg clone operations to pre-generated
files hosted on highly scalable services results in faster clones for
clients and drastically reduces the server requirements for the hg.mozilla.org
service.
See Cloning from Pre-Generated Bundles and the Cloning from S3 blog post for more on clone bundles.