Replication¶
As described at Architecture, hg.mozilla.org consists of
a read/write master server available via SSH and a set of read-only
mirrors available over HTTP. As changes are pushed to the master server,
they are replicated to the read-only mirrors.
VCSReplicator Introduction¶
Version Control System Replicator (vcsreplicator - pylib/vcsreplicator) is
a modern system for replicating version control data.
vcsreplicator is built on top of a distributed transaction log. When changes (typically pushes) are performed, an event is written to the log. Downstream consumers read from the log (hopefully in near real time) and replay changes that were made upstream.
The distributed transaction log is built on top of Apache Kafka <https://kafka.apache.org/>. Unlike other queueing and message delivery systems (such as AMQP/RabbitMQ), Kafka provides guarantees that satisfy our requirements. Notably:
Kafka is a distributed system and can survive a failure in a single node (no single point of failure).
Clients can robustly and independently store the last fetch offset. This allows independent replication mirrors.
Kafka can provide delivery guarantees matching what is desired (order preserving, no message loss for acknowledged writes).
It’s fast and battle tested by a lot of notable companies.
For more on the subject of distributed transaction logs, please read this excellent article from the people behind Kafka.
vcsreplicator is currently designed to replicate changes from a single leader Mercurial server to several, independent mirror servers. It supports replicating:
changegroup data
pushkey data (bookmarks, phases, obsolescence markers, etc)
hgrc config files
repository creation
Architecture¶
A cluster of servers form a Kafka cluster to expose a single logical network service. On hg.mozilla.org, that cluster looks like the following:
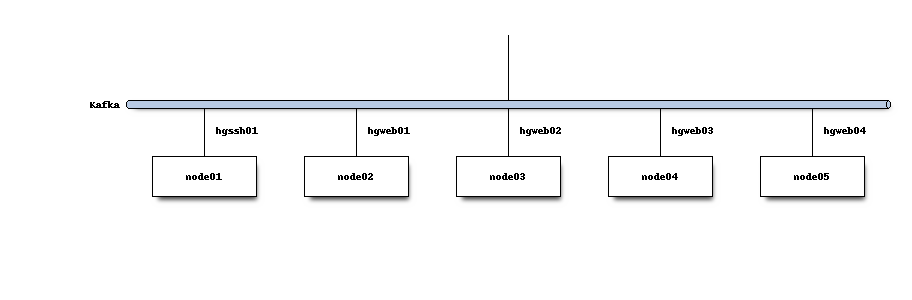
A Kafka topic (i.e. a message queue) is created for messages describing repository change events.
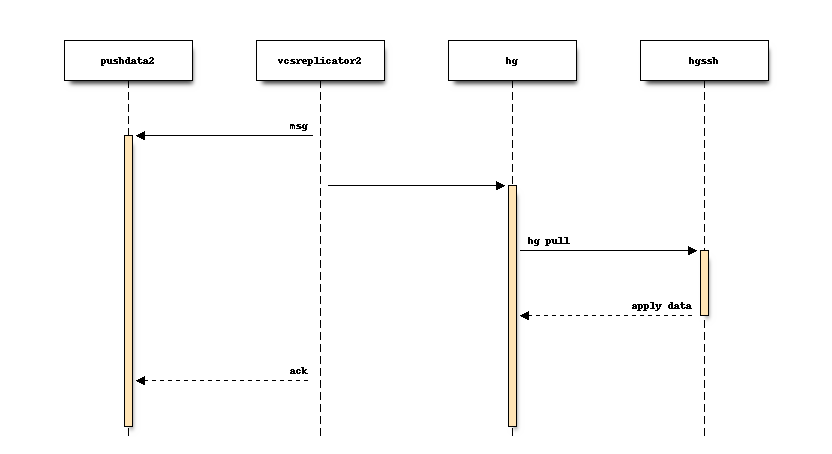
A Mercurial extension is installed on the leader server (the server where writes go). When a Mercurial repository is changed, a new message is published to Kafka.
For example, when a repository is created:

And when a new push occurs:

The published messages contain the repository name and details about the change that occurred.
Publishing to Kafka and Mercurial’s transaction are coupled: if we cannot write messages to Kafka, the repository change operation is prevented or rolled back.
At a lower level on hg.mozilla.org, the pushdata Kafka topic contains
8 partitions and repository change messages are written into 1 of 8 of those
partitions.
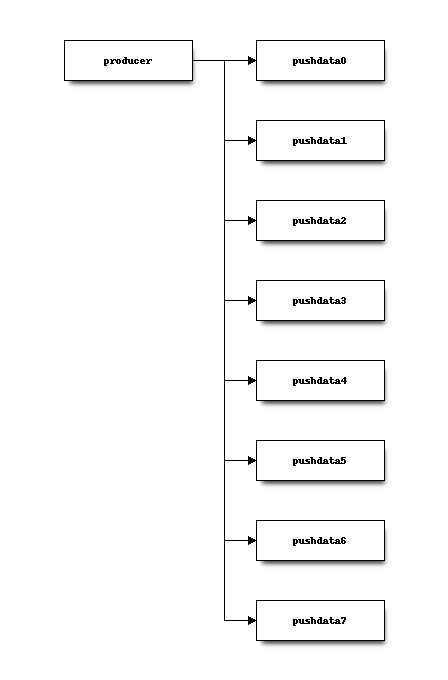
Each repository deterministically writes to the same partition via a name-based
routing mechanism plus hashing. For example, the foo repository may always
write to partition 1 but the bar repository may always write to
partition 6.
Messages published to Kafka topics/partitions are ordered: if message A is
published before message B, consumers will always see A before B.
This means the messages for a given repository are always consumed in
chronological order.
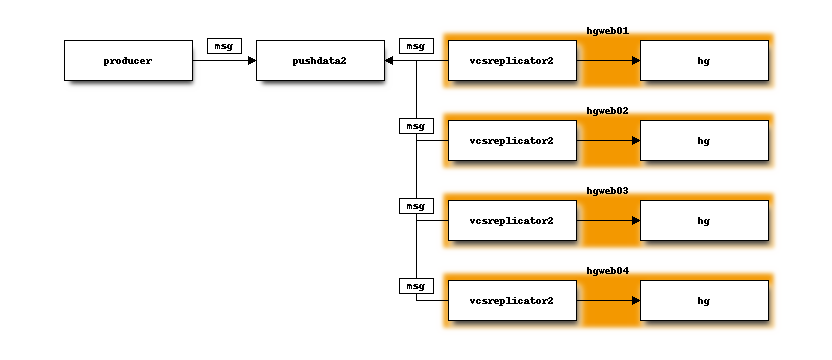
On each mirror, a vcsreplicator-consumer daemon process is bound to each
partition in the pushdata topic. These processes essentially monitor each
partition for new messages.
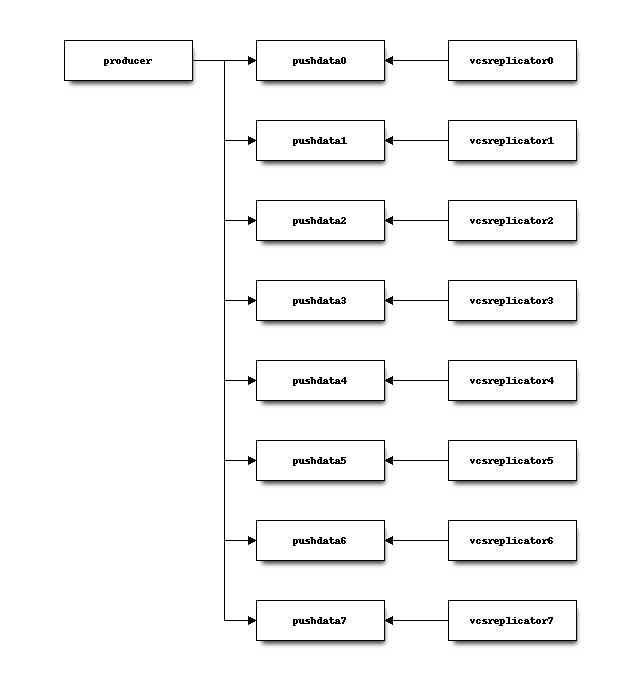
When a new message is written to the partition, the consumer daemon reacts to
that message. The consumer daemon then takes an appropriate action for each
message, often by invoking an hg process to complete an action. e.g.
when a repository is created:
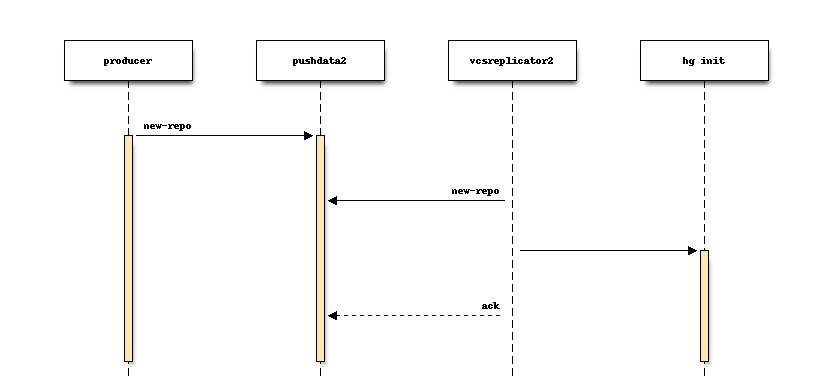
Sometimes the replicated data is too large to fit in a Kafka message. In that case, the consumer will connect to the leader server to obtain data.
Consumers react to new messages within milliseconds of them being published. And the same activity is occurring on each consumer simultaneously and independently.
Consumers typically fully process a message within a few seconds. Events corresponding to big changes (such as cloning a repository, large pushes, etc) can take longer - sometimes minutes.
We rely on repository change messages to have deterministic side-effects. i.e. independent consumers starting in the same state that apply the same stream of messages should end up in an identical state. In theory, a consumer could start from the very beginning of a Kafka topic, apply every message, and arrive at an identical state as the leader.
Consumers only process a single message per topic-partition simultaneously. This is to ensure complete ordering of messages for a given repository and to ensure that messages are successfully processed at most once.
After a consumer successfully performs actions in reaction to a published message, it acknowledges that Kafka message. Once a consumer has acknowledged a message, that message will never be delivered to that consumer again.
Kafka tracks acknowledged messages by recording the offset of the last acknowledged message within a given topic-partition.
Each mirror maintains its own offsets into the various topic-partitions. If a mirror goes offline, Kafka will durably store messages. When the consumer process comes back online, it will resume consuming messages at the last acknowledged offset, picking up where it left off when it disconnected from Kafka.
Aggregated Push Data¶
Repository change messages may be written into multiple partitions to facilitate parallel consumption. Unfortunately, this loses total ordering of messages since there is no ordering across Kafka partitions.
In addition, consumers - being on separate servers - don’t react to and acknowledge messages at exactly the same time. i.e. there is always a window of time between message publish and it being fully consumed where different consumers have different repository states due to being in different phases of processing a message. As an example, a fast server may take 1s to process a push to a repository but a slow server may take 2s. There is a window of 1s where one server has new state and another has old state. Exposing inconsistent state can confuse repository consumers.
The leader server runs a daemon that monitors the partition consumer offsets
for all active consumers. When all active consumers have acknowledged a
message, the daemon re-published that fully-consumed message in a separate
Kafka topic - replicatedpushdatapending on hg.mozilla.org.
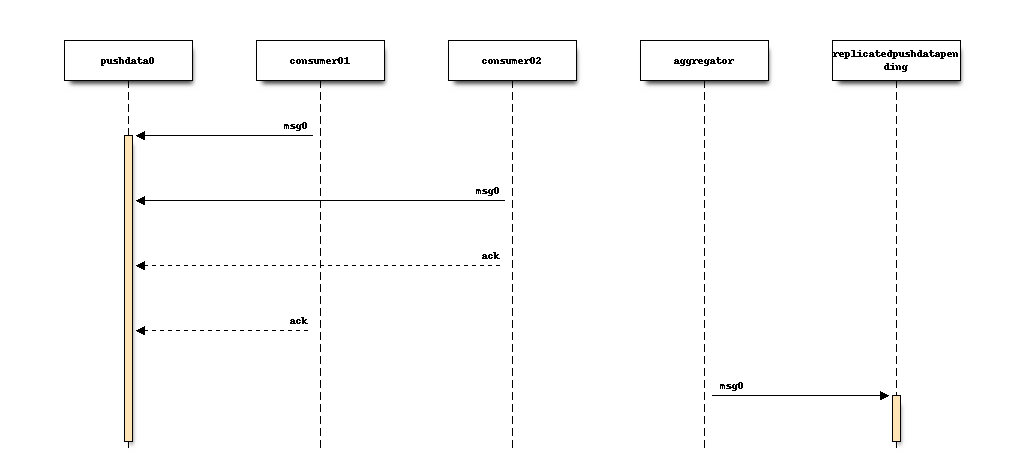
There is a single partition in the replicatedpushdatapending topic, which
means all messages for all repositories are available in a single, ordered
stream. And those messages aren’t exposed until all active consumers have
processed them.
Each mirror runs a daemon that subscribes to this single topic-partition. This daemon will take appropriate actions for each received message before acknowledging it.
The leader server also monitors consumer offsets in the
replicatedpushdatapending topic-partition. When a message is fully consumed,
it is re-published to the replicatedpushdata Kafka topic.
The stream of messages in the replicatedpushdata Kafka topic represents all
fully-replicated repository changes acknowledged by all consumers.
This stream of fully-replicated messages can be consumed by consumers wish to react to events. e.g. on hg.mozilla.org, we have a daemon that publishes messages to Pulse (a RabbitMQ broker) and Amazon SNS so 3rd party consumers can get a notification when a repository even occurs and then implement their own derived actions (such as triggering CI against new commits).
Minimizing the Inconsistency Window for Exposed Data¶
As mentioned above, there is a race condition between the
vcsreplicator-consumer processes on different servers fully processing
and acknowledging a message written to the pushdata topic. This can
lead to different servers exposing different repository state at any given
time.
We minimize this window by employing a multi-stage commit to expose new repository data.
The stream of repository change messages being written by the leader
includes a message containing the set of revisions that are DAG heads that
should be exposed by servers. When this message is initially published
to the pushdata topic, the vcsreplicator-consumer process performs
a no-op when it sees this message. But the message is copied into the
replicatedpushdatapending topic when its offset is acknowledged.
The hgweb servers run a vcsreplicator-headsconsumer process that
is similar to the vcsreplicator-consumer process, except it only
performs meaningful action for these messages containing repository
DAG heads.
When vcsreplicator-headsconsumer sees a heads message, it atomically
writes out a file containing the set of repository heads. Then it
acknowledges the message.
A Mercurial extension loaded into the hgweb processes teaches Mercurial to use the file containing repository heads to determine what data to publicly expose on the server. Even if the repository contains new repository data, unless the new data is listed in the heads file, it won’t be visible to repository consumers.
The vcsreplicator-headsconsumer process is running on each mirror
and the actions it is performing are occurring independently: there is
no central/shared data store recording which heads to expose. This means
there is still a race condition where each server writes out heads files
at a different pace. However, because the vcsreplicator-headsconsumer
process is only writing out (usually) small files and because the process
runs at elevated priority, the timings on different servers is usually
very tight and the inconsistency window is thus very short - often just a
few milliseconds. This window is so short as to not pose a significant
problem.
Known Deficiencies¶
Reliance on hg pull¶
Currently, pushing of new changegroup data results in hg pull being
executed on mirrors. hg pull is robust and mostly deterministic. However,
it does mean that mirrors must connect to the leader server to perform
the replication. This means the leader’s availability is necessary to perform
replication.
A replication system more robust to failure of the leader would store all data in Kafka. As long as Kafka is up, mirrors would be able to synchronize. Another benefit of this model is that it would likely be faster: mirrors would have all to-be-applied data immediately available and wouldn’t need to fetch it from a central server. Keep in mind that fetching large amounts of data can add significant load on the remote server, especially if several machines are connecting at once.
Another benefit of having all data in the replication log is that we could
potentially store this bundle data in a key-value store (like S3)
and leverage Mercurial’s built in mechanism for serving bundles from remote
URLs. The Mercurial server would essentially serve hg pull requests by
telling clients to fetch data from a scalable, possibly distributed
key-value store (such as a CDN).
A benefit of relying on hg pull based replication is it is simple:
we don’t need to reinvent Mercurial data storage. If we stop using hg
pull, various types of data updates potentially fall through the cracks,
especially if 3rd party extensions are involved. Also, storing data in
the replication log could explode the size of the replication log, leading
to its own scaling challenges.
Inconsistency Window on Mirrors¶
Mirrors replicate independently. And data applied by mirrors is available immediately. Therefore, there is a window (hopefully small) where mirrors have inconsistent state of a repository.
If 2 mirrors are behind the same load balancer and requests are randomly
routed to each of the mirrors, there is a chance a client may encounter
inconsistent state. For example, a client may poll the pushlog to see
what changesets are available then initiate a hg pull -r <rev> to
fetch a just-pushed changeset. The pushlog from an in sync mirror may
expose the changeset. But the hg pull hits an out-of-date mirror and
is unable to find the requested changeset.
There are a few potential mechanisms to rectify this problem.
Mirrors could use shared storage. Mercurial’s built-in transaction semantics ensure that clients don’t read data that hasn’t been fully committed yet. This is done at the filesystem level so any networked filesystem (like NFS) that honors atomic file moves should enable consistent state to be exposed to multiple consumers. However, networked filesystems have their own set of problems, including performance and possibly single points of failure. Not all environments are able to support networked filesystems either.
A potential (and yet unexplored) solution leverages ZooKeeper and
Mercurial’s filtered repository mechanism. Mercurial’s repository
access layer goes through a filter that can hide changesets from the
consumer. This is frequently encountered in the context of obsolescence
markers: obsolescence markers hide changesets from normal view. However,
the changesets can still be accessed via the unfiltered view, which can
be accessed by calling a hg command with the --hidden argument.
It might be possible to store the set of fully replicated heads for a given repository in ZooKeeper. When a request comes in, we look up which heads have been fully replicated and only expose changesets up to that point, even if the local repository has additional data available.
We would like to avoid an operational dependency on ZooKeeper (and Kafka) for repository read requests. (Currently, reads have no direct dependency on the availability of the ZooKeeper and Kafka clusters and we’d like to keep it this way so points of failure are minimized.) Figuring out how to track replicated heads in ZooKeeper so mirrors can expose consistent state could potentially introduce a read-time dependency.
Related to this problem of inconsistent state of mirrors is knowing when to remove a failing mirror from service. If a mirror encounters a catastrophic failure of its replication mechanism but the Mercurial server is still functioning, we would ideally detect when the mirror is drifting out of sync and remove it from the pool of mirrors so clients don’t encounter inconsistent state across the mirror pool. This sounds like an obvious thing to do. But automatically removing machines can be dangerous, as being too liberal in yanking machines from service could result in removing machines necessary to service current load. When you consider that replication issues tend to occur during periods of high load, you can imagine what bad situations automatic decisions could get us in. Extreme care must be practiced when going down this road.
Data Loss¶
Data loss can occur in a few scenarios.
Depending on what data is changed in the push, a single push may result in multiple replication messages being sent. For example, there could be a changegroup message and a pushkey message. The messages aren’t written to Kafka as an atomic unit. Therefore, it’s possible for 1 message to succeed, the cluster to fail, and the next message to fail, leaving the replication log in an inconsistent state.
In addition, messages aren’t sent until after Mercurial closes the transaction committing data to the repository. It’s therefore possible for the transaction to succeed but the message send to fail.
Both scenarios are mitigated by writing a no-op heartbeat message into the replication log as one of the final steps before transaction close. If this heartbeat can’t be send, the transaction is aborted. The reasoning here is that by testing the replication log before closing the transaction, we have a pretty good indication whether the replication log will be writeable after transaction close. However, there is still a window for failure.
In the future, we should write a single replication event to Kafka for each push (requires bundle2 on the client) or write events to Kafka as a single unit (if that’s even supported). We should also support rolling back the previous transaction in Mercurial if the post transaction close message(s) fails to write.
Installation and Configuring¶
vcsreplicator requires Python 2.7+, access to an Apache Kafka cluster, and an existing Mercurial server or repository.
For now, we assume you have a Kafka cluster configured. (We’ll write the docs eventually.)
Mercurial Extension Installation¶
On a machine that is to produce or consume replication events, you will need to install the vcsreplicator Python package:
$ pip install /version-control-tools/pylib/vcsreplicator
On the leader machine, you will need to install a Mercurial extension.
Assuming this repository is checked out in /version-control-tools, you
will need the following in an hgrc file (either the global one or one
inside a repository you want replicated):
[extensions]
# Load it by Python module (assuming it is in sys.path for the
# Mercurial server processes)
vcsreplicator.hgext =
# Load it by path.
vcsreplicator = /path/to/vcsreplicator/hgext.py
Producer hgrc Config¶
You’ll need to configure your hgrc file to work with vcsreplicator:
[replicationproducer]
# Kafka host(s) to connect to.
hosts = localhost:9092
# Kafka client id
clientid = 1
# Kafka topic to write pushed data to
topic = pushdata
# How to map local repository paths to partions. You can:
#
# * Have a single partition for all repos
# * Map a single repo to a single partition
# * Map multiple repos to multiple partitions
#
# The partition map is read in sorted order of the key names.
# Values are <partition>:<regexp>. If the partitions are a comma
# delimited list of integers, then the repo path will be hashed and
# routed to the same partition over time. This ensures that all
# messages for a specific repo are routed to the same partition and
# thus consumed in a strict first in first out ordering.
#
# Map {repos}/foo to partition 0
# Map everything else to partitions 1, 2, 3, and 4.
partitionmap.0foo = 0:\{repos\}/foo
partitionmap.1bar = 1,2,3,4:.*
# Required acknowledgement for writes. See the Kafka docs. -1 is
# strongly preferred in order to not lose data.
reqacks = -1
# How long (in MS) to wait for acknowledgements on write requests.
# If a write isn't acknowledged in this time, the write is cancelled
# and Mercurial rolls back its transaction.
acktimeout = 10000
# Normalize local filesystem paths for representation on the wire.
# This both enables replication for listed paths and enables leader
# and mirrors to have different local filesystem paths.
[replicationpathrewrites]
/var/repos/ = {repos}/
Consumer Config File¶
The consumer daemon requires a config file.
The [consumer] section defines how to connect to Kafka to receive
events. You typically only need to define it on the follower nodes.
It contains the following variables:
- hosts
Comma delimited list of
host:portstrings indicating Kafka hosts.- client_id
Unique identifier for this client.
- connect_timeout
Timeout in milliseconds for connecting to Kafka.
- topic
Kafka topic to consume. Should match producer’s config.
- group
Kafka group the client is part of.
You should define this to a unique value.
The [path_rewrites] section defines mappings for how local filesystem
paths are normalized for storage in log messages and vice-versa.
This section is not required. Presence of this section is used to abstract storage-level implementation details and to allow messages to define a repository without having to use local filesystem paths. It’s best to explain by example. e.g.:
[path_rewrites]
/repos/hg/ = {hg}/
If a replication producer produces an event related to a repository under
/repos/hg/ - let’s say /repos/hg/my-repo, it will normalize the
path in the replication event to {hg}/my-repo. You could add a
corresponding entry in the config of the follower node:
[path_rewrites]
{hg}/ = /repos/mirrors/hg/
When the consumer sees {hg}/my-repo, it will expand it to
/repos/mirrors/hg/my-repo.
Path rewrites are very simple. We take the input string and match against registered rewrites in the order they were defined. Only a leading string search is performed - we don’t match if the first character is different. Also, the match is case-insensitive (due to presence of case-insensitive filesystems that may report different path casing) but case-preserving. If you have camelCase in your repository name, it will be preserved.
The [pull_url_rewrites] section is used to map repository paths
from log messages into URLs suitable for pulling from the leader.
They work very similarly to [path_rewrites].
The use case of this section is that it allows consumers to construct URLs to the leader repositories at message processing time rather than message produce time. Since URLs may change over time (don’t tell Roy T. Fielding) and since the log may be persisted and replayed months or even years later, there needs to be an abstraction to redefine the location of a repository later.
Note
The fact that consumers perform an hg pull and need URLs to pull
from is unfortunate. Ideally all repository data would be
self-contained within the log itself. Look for a future feature
addition to vcsreplicator to provide self-contained logs.
Aggregator Config File¶
The aggregator daemon (the entity that copies fully acknowledged messages into a new topic) has its own config file.
All config options are located in the [aggregator] section. The following
config options are defined.
- hosts
Comma delimited list of
host:portstrings indicating Kafka hosts.- client_id
Unique identifier for this client.
- connect_timeout
Timeout in milliseconds for connecting to Kafka.
- monitor_topic
The Kafka topic that will be monitored (messages will be copied from).
- monitor_groups_file
Path to a file listing the Kafka groups whose consumer offsets will be monitored to determine the most recent acknowledged offset. Each line in the file is the name of a Kafka consumer group.
- ack_group
The consumer group to use in
monitor_topicthat the aggregator daemon will use to record which messages it has copied.- aggregate_topic
The Kafka topic that messages from
monitor_topicwill be copied to.
Upgrading Kafka¶
It is generally desirable to keep Kafka on an up-to-date version, to benefit from bugfixes and performance improvements. Upgrading the hg.mozilla.org Kafka instances can be done via a rolling upgrade, allowing the replication system to continue working with no downtime. Kafka also uses Apache Zookeeper as a distributed configuration service, and you may wish to upgrade Zookeeper at the same time as Kafka. The steps to do so are as follows:
Note
While these steps will likely cover all upgrade requirements, there is no guarantee that Apache will not change the upgrade process in the future. Make sure to check the release notes for any breaking changes to both application code and the upgrade procedure before moving forward.
Note
You should perform the Zookeeper and Kafka upgrades independently, to minimize the risk of failure and avoid debugging two applications if something goes wrong. See https://kafka.apache.org/documentation/#upgrade and https://wiki.apache.org/hadoop/ZooKeeper/FAQ#A6
Steps for both applications¶
Both Kafka and Zookeeper are deployed from a tarball which is uploaded to a Mozilla owned Amazon S3 bucket. We need to upload our new Kafka/Zookeeper tarballs to this bucket and keep their SHA 256 hashsum to ensure the correct file is downloaded.
- Upload new package archives to
https://s3-us-west-2.amazonaws.com/moz-packages/<package name>
Calculate the sha256 hash of the uploaded archives.
Update version-control-tools/ansible/roles/kafka-broker/tasks/main.yml with the new package names and hashes.
Zookeeper¶
To upgrade Zookeeper, simply deploy the updated code to hg.mozilla.org and then run systemctl restart zookeeper serially on each host to perform the upgrade. Easy!
Kafka¶
To upgrade Kafka, some additional steps must be performed if message format or wire protocol changes have been made between your current and updated versions. For example, when upgrading from 0.8.2 to 1.1.0, both message formats and wire protocol changes were made, so all of the following changes must be made.
Before updating the code, advertise the message format and protocol versions used by the current Kafka instance in the server config (kafka-server.properties) using the following properties: - inter.broker.protocol.version=CURRENT_KAFKA_VERSION - log.message.format.version=CURRENT_MESSAGE_FORMAT_VERSION
Deploy code in the previously updated archive to hg.mozilla.org.
Serially run systemctl restart kafka.service on each broker to update the code.
Update inter.broker.protocol.version to the version of Kafka you are upgrading to and run systemctl restart kafka.service serially once again.
Update log.message.format.version to the version of Kafka you are upgrading to and run systemctl restart kafka.service serially once again.
Note
After running each of the restart commands, you should tail the Kafka logs on the newly updated server, as well as a server that has yet to be updated, to make sure everything is working smoothly.